Recently we concluded a project to extract traffic data from tweets of road.lk. This post would be one post of many posts to connect a few dots of our project. My friend Achintha has connected more than a few dots in his blog. I will post links to relevant parts as i proceed with this post.
Initially let me give a brief introduction to the mischief we caused in this project. Our initial aim was to add support to sending events from Apache UIMA framework into the WSO2 Complex Event Processor. We concluded the project by implementing a real world use case of Extracting traffic details using tweets(from road.lk) and Apache UIMA framework and sending the extracted details as events to WSO2 Complext event processor.
I know many of these terms are new, so let me start by describing some of these and i have included relevant links so that those of you who are interested can do some further reading.
Apache UIMA(Unstructured Information Management Architecture)
Apache UIMA is a framework to extract structured data from mass volumes of unstructured data. These unstructured data can be emails,text documents, images, videos and in our case it was tweets. Imagine UIMA as a pipe, you feed it any garbage(unstructured data) and out comes gold(the structured data). You can find more about UIMA here.
WSO2 Complex Event Processor
WSO2 CEP is one of the leading open source products which provides complex event processing, with a promise to deliver the capability to process over 2.5M events per second. Think of the CEP as an engine that takes in bullet fired at a rapid rate do some processing(may be engrave your name) and send them out as if it was never stopped on its path. You can find more about WSO2 CEP here.

So our project basically consisted of few stages,
Since we had to integrate few technologies together we had to identify few key integration points.
I would be focusing on the integration points in my posts as rest of the dots have been connected by Achintha in his blog. This blog post would focus on the integration point between the UIMA framework and WSO2 CEP. Expect the others in future posts.
Before i jump into details just to get an idea and to make things clear have a look at the overview design of our system,
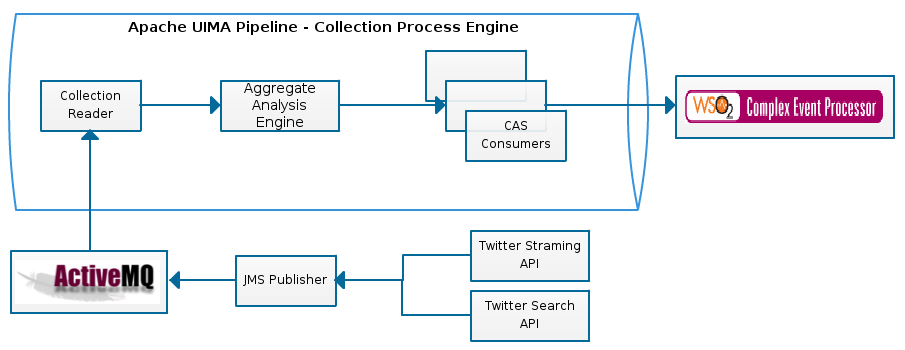
The Apache UIMA Framework provide an easy to use pipeline like Collection Processing Engine which processes a collection of unstructured data and sends extracted data out of the pipeline. To understand how the Collection Processing works, you may refer here.
So basically you could see all the integration points except the CEP ---> UI in the above diagram.
We used Apache ActiveMQ to connect the twitter client and the Collection Reader(The components that pulls in unstructured data in for analysis). We will discuss this in a later post.
So we managed to get in the tweets from the ActiveMQ broker, what we basically do in the Collection Reader is to create CAS(Common Analysis System) using the tweet text. Nothing fancy here, simply think of the CAS as an object which stores text or whatever the unstructured data that came in. We also use the same CAS for storing the extracted meta data. So the CAS is one packaged box that contains the document text(tweet text in our case) and the extracted meta data(traffic location and traffci level). The extracted meta data are added to the CAS when they are sent through UIMA aggregate analysis engines.
In order to get an idea on the writing analysis engines to extract and some other cool stuff we did to extract traffic details from tweets read this and the follow ups in Achintha's blog.
So now that the CAS has been filled with extracted data, it has to be consumed or in simple terms be used. CAS Consumers are components of the UIMA pipeline(rather the Collection Processing Engine) that do exactly this.
Consuming CASes is like opening a package of toys and playing with it. You can literally do anything with the CAS you have. You can simply print the extracted texts(in UIMA jargon we call it annotated text) on the console, log into a file, store in a database or send it over to someone else to consume.
So in our case we chose the CAS consumer to be the integration point between the UIMA Collection Processing Engine and the WSO2 CEP.
Writing a CAS Consumer is similar to writing any other UIMA Component, you need to:
Writing the Java class for the Cas Consumer is quite simple, you need to have the apache-uima libraries in you build path for this or you need to declare required dependencies in a pom(For maven projects).
Once you have the libraries in you build path simply create a java class and extend CasConsumer_ImplBase. Upon extending you will be required to override
processCas(CAS arg0) method which contains the logic for consuming the CAS.

For now lets leave the java class as it is and move on to the descriptor file. We will come back to the java class once we complete the descriptor file.
Writing the descriptor file is quite easy if you setup UIMA tooling on Eclipse. If you setup the UIMA tooling on eclipse then descriptor files can be generated using the GUI provided by the tools by filling up forms easily. Use the guide provided by Apache UIMA for this.
So once you are set up, you can start creating a descriptor file by selecting "Cas Consumer Descriptor File" type from the New menu,

After giving an appropriate name and a parent folder you will need to fill in the details,

Most important point here is that you need to give the fully qualified name of the implementation Java class of the CasConsumer. For the above create class the full qualified name would be org.wso2.uima.collectionProccesingEngine.consumers.TestCasConsumer.
Apart from this you can also specify many other things using the Descriptor Editor. One such important addition would be to specify configuration parameters which can be extracted at run time using the framework.
For example say you are writing a Cas Consumer to send out extracted data to a server, in that case you need to store the URL of the server somewhere, rather than hard coding this or using a property the UIMA framework provides an easy way to get this configuration parameters from the descriptor file.
To add a configuration parameter, go to the Parameters tab and add,

You can assign a value to the config parameter by going to the Parameter Settings tab,

Now that we have completed the descriptor file, Save it and take a look at the XML in Source view( Click on the Source tab). You should see something like this,
As I mentioned above the configuration parameter value can be accessed in the code simply by,
Right now that you know the inside out of a Cas Consumer Descriptor file. Lets get back to the java class that we left uncompleted.
Though you only need to override the processCas(CAS arg0) of the java class. Actually in our case we decided to override the initialize() method of the Cas Consumer class as well. There is a valid reason for this. I will explain as we go along. The WSO2 CEP provided a number of input event adaptors which are basically the connection points we could make our Cas Consumers talk to. As of WSO2 3.1.0 it provides ,
So our project basically consisted of few stages,
- Take in tweets in real time
- Send the tweets through Apache UIMA Framework and extract traffic data
- Send the extracted data as events to the WSO2 Complex Event Processor
- Process the event within the WSO2 Complex Event Processor
- Send out processed events to the Web UI
Since we had to integrate few technologies together we had to identify few key integration points.
- Twitter ---> UIMA framework
- UIMA Framework ---> WSO2 CEP
- WSO2 CEP ---> Web UI
Before i jump into details just to get an idea and to make things clear have a look at the overview design of our system,
The Apache UIMA Framework provide an easy to use pipeline like Collection Processing Engine which processes a collection of unstructured data and sends extracted data out of the pipeline. To understand how the Collection Processing works, you may refer here.
So basically you could see all the integration points except the CEP ---> UI in the above diagram.
We used Apache ActiveMQ to connect the twitter client and the Collection Reader(The components that pulls in unstructured data in for analysis). We will discuss this in a later post.
So we managed to get in the tweets from the ActiveMQ broker, what we basically do in the Collection Reader is to create CAS(Common Analysis System) using the tweet text. Nothing fancy here, simply think of the CAS as an object which stores text or whatever the unstructured data that came in. We also use the same CAS for storing the extracted meta data. So the CAS is one packaged box that contains the document text(tweet text in our case) and the extracted meta data(traffic location and traffci level). The extracted meta data are added to the CAS when they are sent through UIMA aggregate analysis engines.
In order to get an idea on the writing analysis engines to extract and some other cool stuff we did to extract traffic details from tweets read this and the follow ups in Achintha's blog.
So now that the CAS has been filled with extracted data, it has to be consumed or in simple terms be used. CAS Consumers are components of the UIMA pipeline(rather the Collection Processing Engine) that do exactly this.
Consuming CASes is like opening a package of toys and playing with it. You can literally do anything with the CAS you have. You can simply print the extracted texts(in UIMA jargon we call it annotated text) on the console, log into a file, store in a database or send it over to someone else to consume.
So in our case we chose the CAS consumer to be the integration point between the UIMA Collection Processing Engine and the WSO2 CEP.
Writing a CAS Consumer is similar to writing any other UIMA Component, you need to:
- A Java Class that says how we consumer the CAS (We simply need to extend a base class and override methods)
- Write a descriptor file (XML file that has all the config stuff)
Writing the Java class for the Cas Consumer is quite simple, you need to have the apache-uima libraries in you build path for this or you need to declare required dependencies in a pom(For maven projects).
Once you have the libraries in you build path simply create a java class and extend CasConsumer_ImplBase. Upon extending you will be required to override
processCas(CAS arg0) method which contains the logic for consuming the CAS.
For now lets leave the java class as it is and move on to the descriptor file. We will come back to the java class once we complete the descriptor file.
Writing the descriptor file is quite easy if you setup UIMA tooling on Eclipse. If you setup the UIMA tooling on eclipse then descriptor files can be generated using the GUI provided by the tools by filling up forms easily. Use the guide provided by Apache UIMA for this.
So once you are set up, you can start creating a descriptor file by selecting "Cas Consumer Descriptor File" type from the New menu,
After giving an appropriate name and a parent folder you will need to fill in the details,
Most important point here is that you need to give the fully qualified name of the implementation Java class of the CasConsumer. For the above create class the full qualified name would be org.wso2.uima.collectionProccesingEngine.consumers.TestCasConsumer.
Apart from this you can also specify many other things using the Descriptor Editor. One such important addition would be to specify configuration parameters which can be extracted at run time using the framework.
For example say you are writing a Cas Consumer to send out extracted data to a server, in that case you need to store the URL of the server somewhere, rather than hard coding this or using a property the UIMA framework provides an easy way to get this configuration parameters from the descriptor file.
To add a configuration parameter, go to the Parameters tab and add,
You can assign a value to the config parameter by going to the Parameter Settings tab,
Now that we have completed the descriptor file, Save it and take a look at the XML in Source view( Click on the Source tab). You should see something like this,
<?xml version="1.0" encoding="UTF-8"?> <casConsumerDescription xmlns="http://uima.apache.org/resourceSpecifier"> <frameworkImplementation>org.apache.uima.java</frameworkImplementation> <implementationName>org.wso2.uima.collectionProccesingEngine.consumers.TestCasConsumer</implementationName> <processingResourceMetaData> <name>TestConsumerDescriptor</name> <description>Description About the Consumer</description> <version>1.0</version> <vendor/> <configurationParameters> <configurationParameter> <name>serverURL</name> <description>URL of the remote server to send extracted data</description> <type>String</type> <multiValued>false</multiValued> <mandatory>true</mandatory> </configurationParameter> </configurationParameters> <configurationParameterSettings> <nameValuePair> <name>serverURL</name> <value> <string>http://localhost:9090/testService/add</string> </value> </nameValuePair> </configurationParameterSettings> <typeSystemDescription/> <fsIndexCollection/> <capabilities> <capability> <inputs/> <outputs/> <languagesSupported/> </capability> </capabilities> <operationalProperties> <modifiesCas>false</modifiesCas> <multipleDeploymentAllowed>true</multipleDeploymentAllowed> <outputsNewCASes>false</outputsNewCASes> </operationalProperties> </processingResourceMetaData> <resourceManagerConfiguration/> </casConsumerDescription>
As I mentioned above the configuration parameter value can be accessed in the code simply by,
String url = (String) getConfigParameterValue("serverURL");
Right now that you know the inside out of a Cas Consumer Descriptor file. Lets get back to the java class that we left uncompleted.
Though you only need to override the processCas(CAS arg0) of the java class. Actually in our case we decided to override the initialize() method of the Cas Consumer class as well. There is a valid reason for this. I will explain as we go along. The WSO2 CEP provided a number of input event adaptors which are basically the connection points we could make our Cas Consumers talk to. As of WSO2 3.1.0 it provides ,
- Input WSO2Event Event Adapter
- Input JMS Event Adapter
- Input SOAP Event Adapter
- Input Email Event Adapter
- Input HTTP Event Adapter
- Input File Event Adapter
- Input Kafka Event Adapter
We implemented WSO2Event Event, SOAP an HTTP Cas Consumers which will sent in events to the CEP via the respective adaptors. I will take you through the WSO2 Event Cas Consumer or rather Databridge Cas Consumer(Make use of WSO2 Carbon Databridge) implementation, other two consumers follow a similar pattern.
In order to write the consumer a brief understanding of the way the Cas Consumer will be handled by UIMA would be important. When we create a UIMA Collection Processing Engine(pipeline) instance what it actually does is to instantiate each of it's constituent components and call their initialize() methods to complete the initialization of the pipeline. So basically when we create a CPE instance it will create a Collection Reader, Analysis Engine and the respective Cas Consumers and then call their initialize() methods.
Therefore we can include all the code related to initializing the Cas Consumer inside the initialize() method, So in the case of Databridge Cas Consumer we,
- setup trust store paramters
- created the data publisher instance
- connected to the server's thrift port using credentials
- defined a stream to send in events.
inside the initialize() method. You can take a look at the source here.
Next we need to extract the data from the Cas and consumer it. We need to do this using the processCas() method which we overrode.
We can extract the annotated(extracted data) by iterating the feature structure(data structure used inside CAS to stored extracted data) as below,
Note: CAS stored the extracted data in the form of Types which are analogous to Objects in Java and the Types contains features which are similar to the attributes of Object in Java.
LocationIdentification in the below code snippet is the Type of extracted data.
Next we need to extract the data from the Cas and consumer it. We need to do this using the processCas() method which we overrode.
We can extract the annotated(extracted data) by iterating the feature structure(data structure used inside CAS to stored extracted data) as below,
Note: CAS stored the extracted data in the form of Types which are analogous to Objects in Java and the Types contains features which are similar to the attributes of Object in Java.
LocationIdentification in the below code snippet is the Type of extracted data.
JCas output = null; try { output = cas.getJCas(); } catch (CASException e2) { } StringBuilder builder = new StringBuilder(); FSIndex locationIndex = output.getAnnotationIndex(LocationIdentification.type); for (Iterator<LocationIdentification> it = locationIndex.iterator(); it.hasNext(); ) { LocationIdentification annotation = it.next(); if (!builder.toString().contains(annotation.getCoveredText())) { builder.append(annotation.getCoveredText() + " "); } } String location = builder.toString().trim();
the processCas() method will be called per CAS by the UIMA CPE . So we need to extract data and send the events within this method. The implementation of this can be found here.
You can define your helper methods to keep you code clean and tidy, but it is important to note that the UIMA CPE will call the initialize() method once per instance of the Cas Consumer and the processCas() method per each CAS inside the pipeline. In our case we create only one CPE for the whole application lifetime and for each tweet that comes in the processCas() method would be called.
You can also take a look at the SOAP Cas Consumer and HTTP Cas Consumer. Basically though these components are consumers inside the UIMA pipeline they are acting as event producers to the WSO2 CEP. In order to use the SOAP and HTTP Cas Consumers you need to add the relevant input adaptors to the CEP flow and use their respective end points as destinations to send events.
I know this has been a long post. I tried to be as clear and descriptive as possible. This is just connecting few dots. Looking forward to writing more on our project. Your feedback is welcome :)
Cheers
You can define your helper methods to keep you code clean and tidy, but it is important to note that the UIMA CPE will call the initialize() method once per instance of the Cas Consumer and the processCas() method per each CAS inside the pipeline. In our case we create only one CPE for the whole application lifetime and for each tweet that comes in the processCas() method would be called.
You can also take a look at the SOAP Cas Consumer and HTTP Cas Consumer. Basically though these components are consumers inside the UIMA pipeline they are acting as event producers to the WSO2 CEP. In order to use the SOAP and HTTP Cas Consumers you need to add the relevant input adaptors to the CEP flow and use their respective end points as destinations to send events.
I know this has been a long post. I tried to be as clear and descriptive as possible. This is just connecting few dots. Looking forward to writing more on our project. Your feedback is welcome :)
Cheers
Comments
Post a Comment